Exploiting Completeness and Uncertainty of Pseudo Labels
Exploiting Completeness and Uncertainty of Pseudo Labels
Motivation
现有方法
paper将现有的弱监督方法分为两种:
- MIL
- two-stage self-training
基于MIL的方法由于缺少clip-level的标注,得到的异常分数常常是较为不精确的。而two-stage self-training 方法的提出可以缓解该问题。
two-stage self-training[5,12]
- 基于MIL方法为clips生成伪标签(pseudo labels)
- 用伪标签去精细化判别表示
limitations
针对two-stage self training 的 Completeness and Uncertainty of Pseudo Labels
用于伪标签生成的ranking loss 忽略异常事件的完整性
“一个正袋可能包含多个异常事件片段,,但是MIL只会检测到最像的一个。”(really?)

橘色部分代表ground truth, 现有的方法如b所示,关注在最异常的片段。因此,提出使用基于diversity loss的多头分类模块,以生成能够覆盖完整异常事件的伪标签(如c所示)
在第二步中 生成伪标签的不确定性 未被考虑
伪标签通常是有噪声的,直接使用进行最后分类模型的训练可能损害模型性能表现。
解决
分别针对两个limitations
- 提出多头模块生成伪标签,引入diversity loss以确保多个分类头生成的伪标签的分布差异→ 确保异常事件的完整性检测 (对应step1)
- 通过这种方式,每一个头倾向于发现不同的异常事件,因此可以让伪标签尽可能覆盖更多的异常事件
- 设计一个迭代的基于不确定性的训练策略 (对应step2)
- 使用Monte Carlo(MC) Dropout 度量不确定性
- 将低不确定性的片段用于最后分类器的训练 (该过程逐渐迭代细化伪标签)
- 第一次迭代 细化 step1生成的伪标签
- 剩余的迭代细化分类器每次迭代的输出伪标签
Contribution
- 我们设计了一个基于多样性损失的多头分类器方案,使得伪标签覆盖尽可能多的异常片段。
- 我们设计了一种迭代的不确定性感知的自我训练策略,以逐步提高伪标签的质量。
- 在UCF-Crime、TAD和XD-Violence上进行的实验表明,与几种最先进的方法相比,它具有良好的性能。
Method
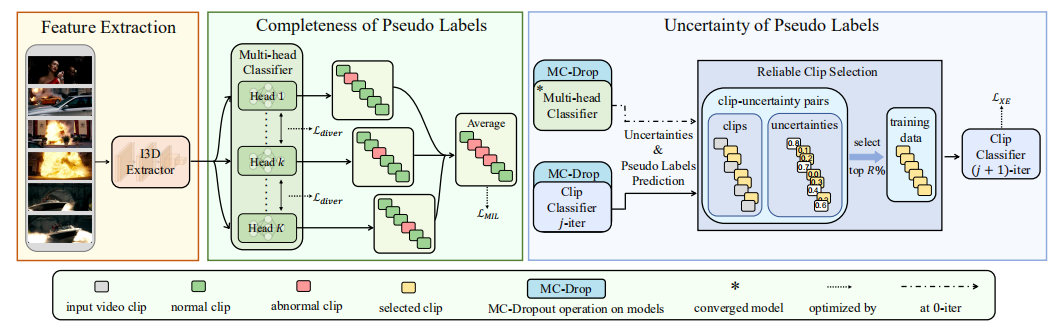
1) 使用预训练的3D CNN模型提取视频特征(paper使用的是I3D)
2)经过多样性损失和MIL排序损失训练的多头分类器来生成初始的片段伪标签
3)利用一个迭代的不确定性感知的伪标签细化策略, 逐步提高伪标签的质量,训练最终期望的分类器。
Completeness Enhanced Pseudo Label Generator
用预先训练好的3D CNN来提取视频特征。将这些特征输入受多样性损失约束的多头分类器,以检测完整的异常事件。
Iterative Uncertainty Aware Pseudo Label Refinement
在第一次迭代中,我们从first stage的多头分类器中获得初始的clip级伪标签,并通过Monte Carlo Dropout计算其不确定性。然后根据不确定性选择可靠的片段来训练一个新的片段分类器。在剩下的迭代中,使用新的片段分类器更新伪标签。
Completeness of Pseudo Labels
伪标签生成器由并行的多头分类器组成。each head由三个全连接层组成
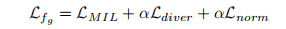
- diversity loss
each head输出每个片段的异常分数,并通过softmax生成分数的分布:
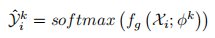
通过多样性损失(diversity loss) 将属于不同head的分数分布互相区分开来← 通过最小化任意两头之间的余弦相似度
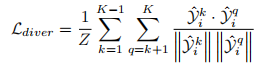
- regularization term
片段分数序列的正则化项:平衡多头并避免由于一头占主导地位导致的性能下降
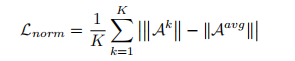
在多样性损失和范数正则化的作用下,多头产生的异常得分可以达到最大的区别,并能够检测不同的异常片段。
sigmoid所有头异常分数的平均得到片段级的标签
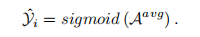
ranking loss
最大化异常和正常实例的差距
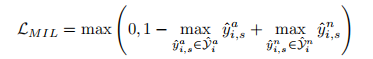
Uncertainty of Pseudo Labels
为了训练最终期望的片段分类器fc,而不是直接使用在step1获得的片段级伪标签 提出了一种不确定性感知的自训练策略挖掘具有可靠伪标签的片段。
具体地说,我们引入了利用Monte Carlo Dropout 的不确定性估计,从而选择具有低不确定性(即可靠的)伪标签的片段进行训练fc。这个过程进行了几次迭代。伪标签最初是在第一阶段获得的,然后进行经由fc更新。

Experimental Results
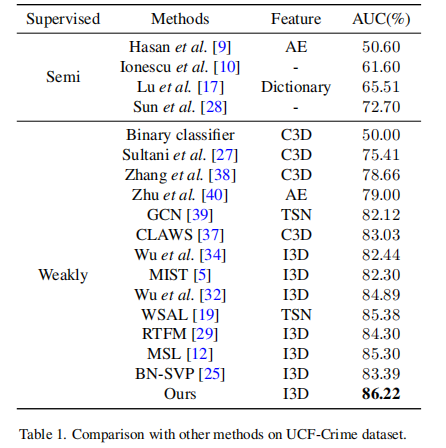
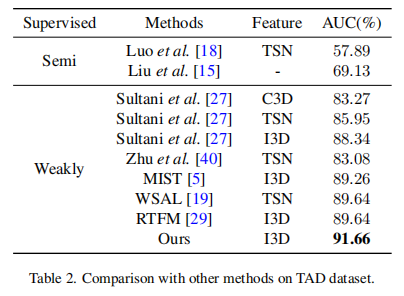
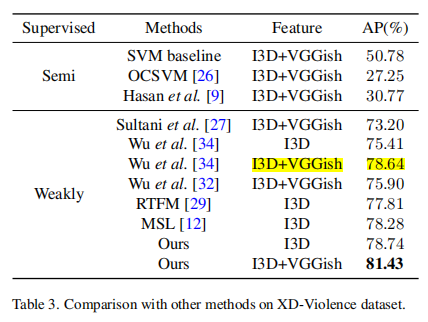
消融实验

超参分析
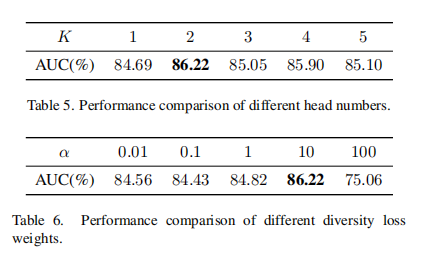
最好的结果是双头